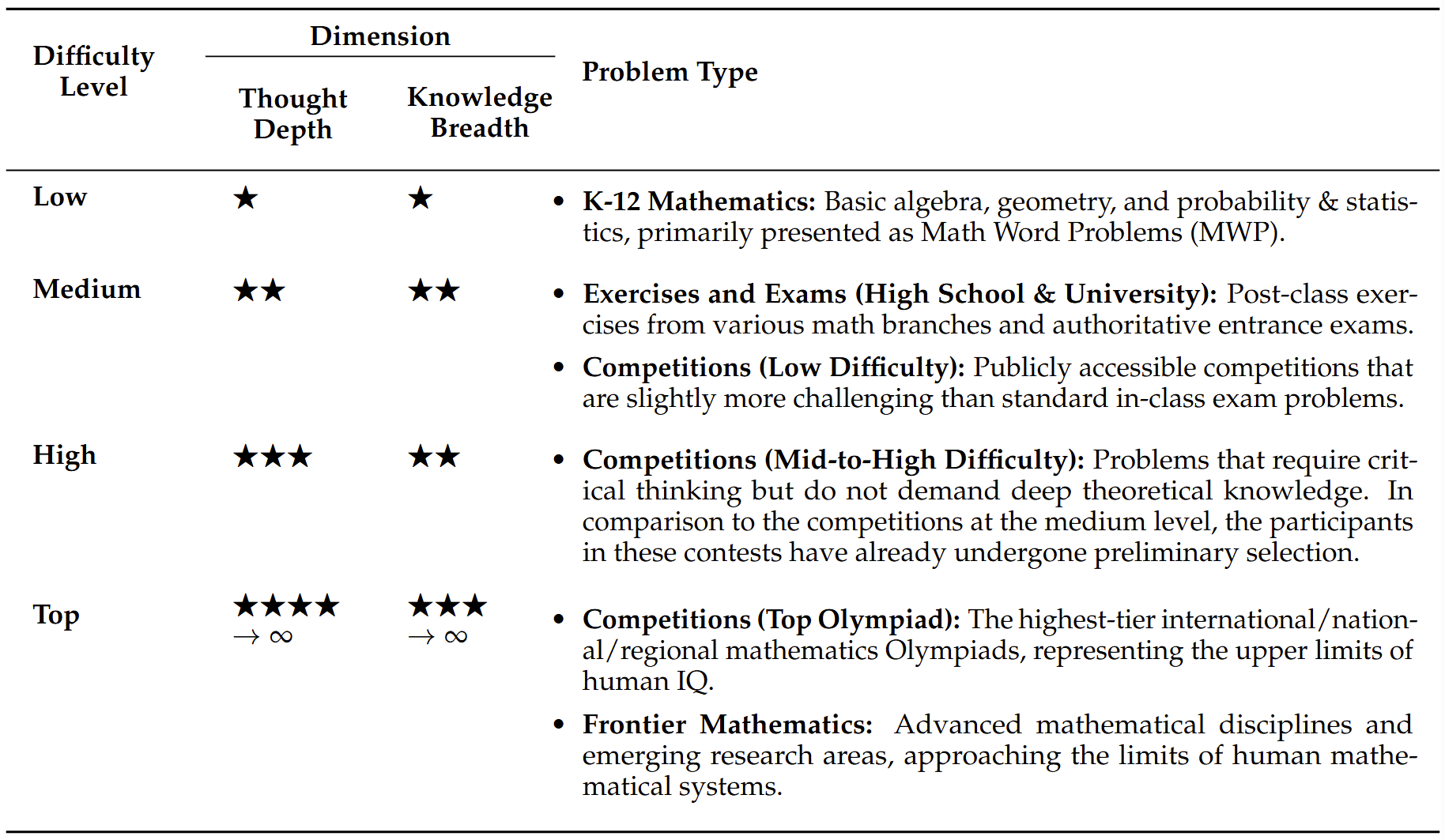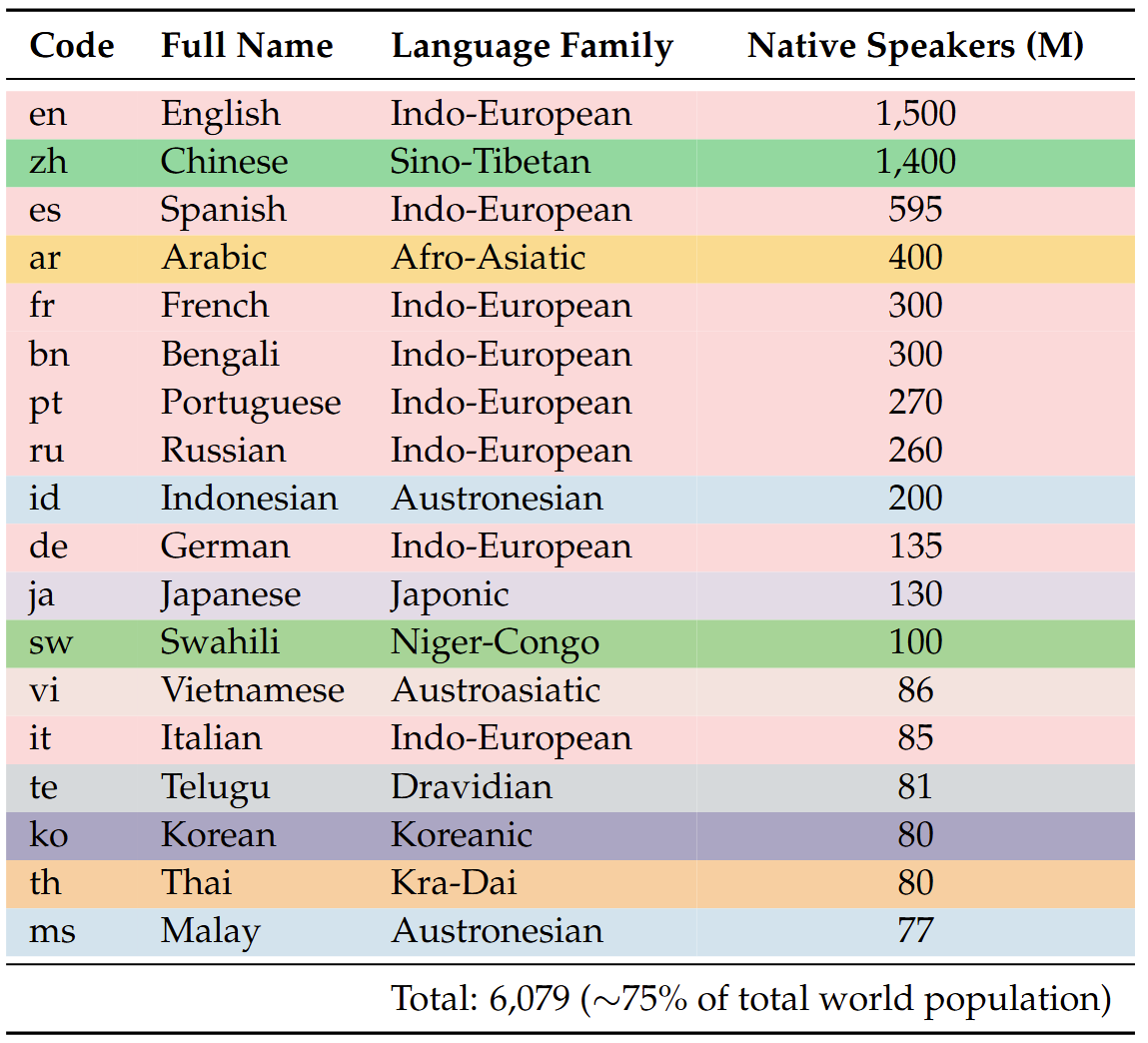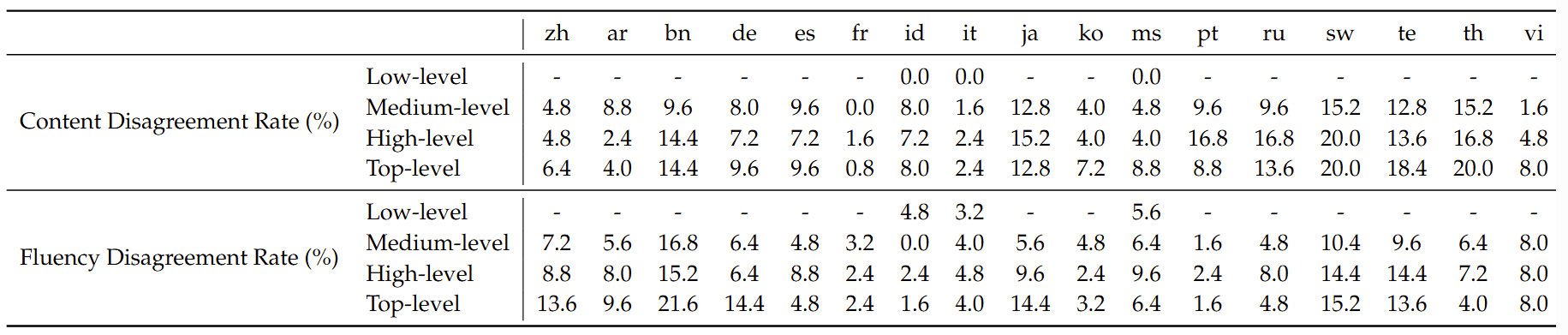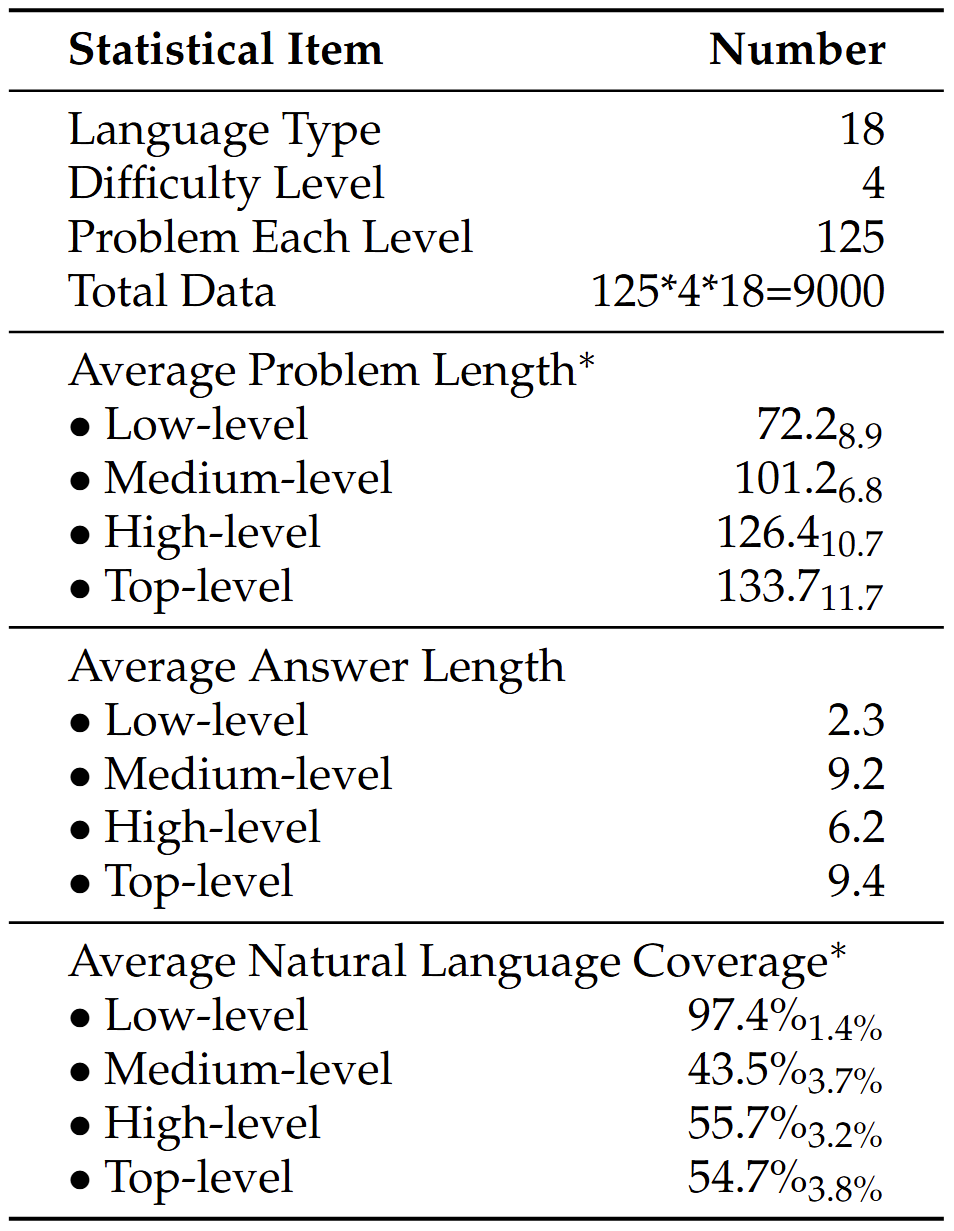
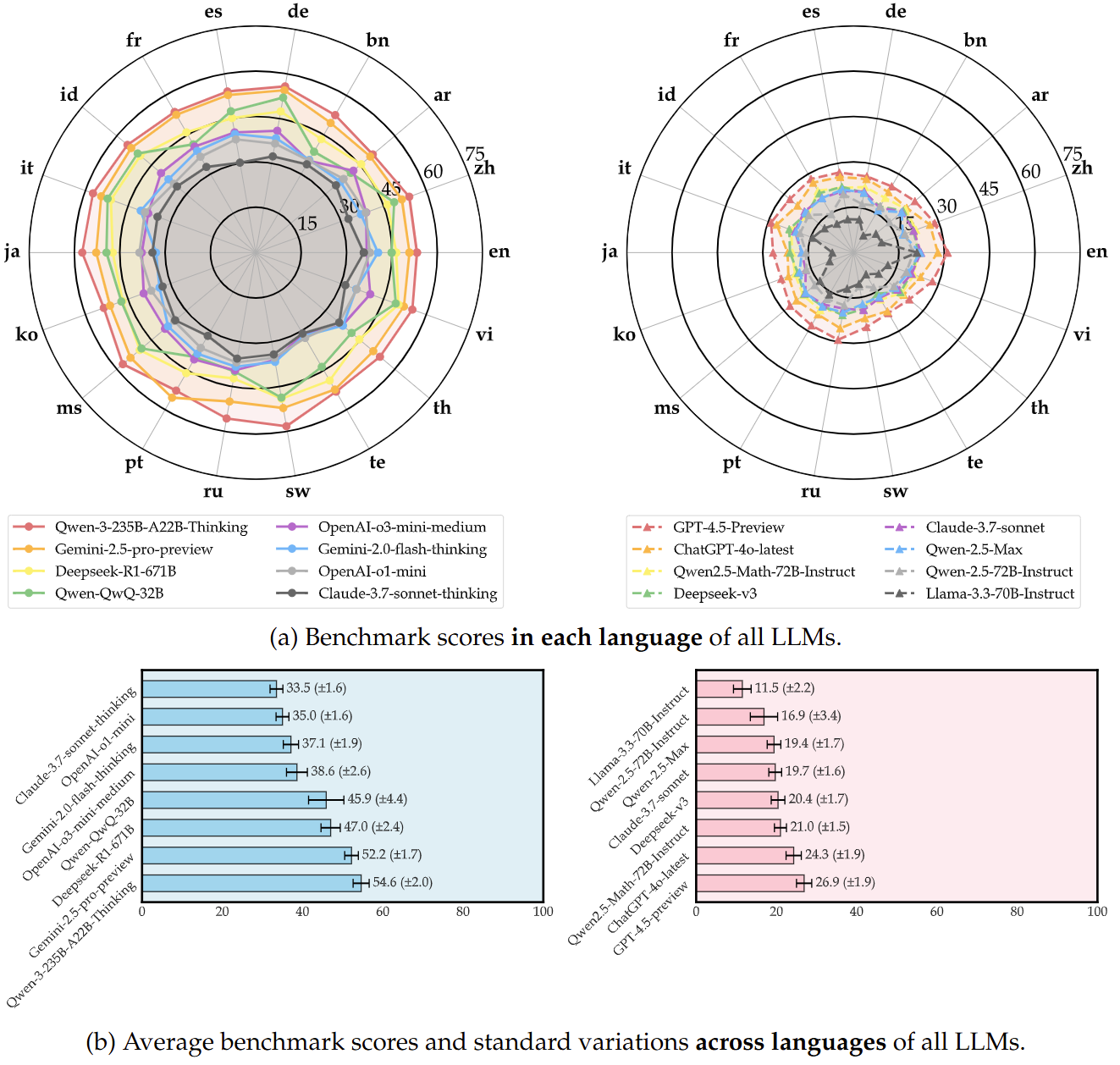
Benchmark Scores (before 2025-05-01) of  PolyMath. “*” represents a reasoning model, otherwise a non-reasoning model.
PolyMath. “*” represents a reasoning model, otherwise a non-reasoning model.
| # | Model | Snapshot | Overall | en | zh | ar | bn | de | es | fr | id | it | ja | ko | ms | pt | ru | sw | te | th | vi | Range (max-min) |
| 1 | *Qwen3-235B-A22B-Thinking🥇 | 2025-04-29 | 54.6 | 55.8 | 54.1 | 53.7 | 53.3 | 55.4 | 57.3 | 57.4 | 53.5 | 57.4 | 52.7 | 55.7 | 54.0 | 58.3 | 53.1 | 50.5 | 52.5 | 53.6 | 55.1 | 7.8 |
| 2 | *Gemini-2.5-pro🥈 | 2025-03-25 | 52.2 | 54.5 | 52.9 | 52.6 | 50.8 | 53.8 | 54.4 | 52.8 | 51.3 | 54.1 | 55.4 | 50.0 | 51.4 | 52.2 | 52.3 | 49.4 | 49.5 | 50.7 | 52.1 | 6.0 |
| 3 | *Qwen3-32B-Thinking🥉 | 2025-04-29 | 47.4 | 49.0 | 46.8 | 47.0 | 45.9 | 48.1 | 51.8 | 47.1 | 45.6 | 49.7 | 47.7 | 48.5 | 48.5 | 52.4 | 46.5 | 43.7 | 44.2 | 46.9 | 44.0 | 8.6 |
| 4 | *Seed-Thinking-v1.5 | 2025-04-15 | 47.2 | 51.6 | 46.6 | 47.3 | 45.4 | 47.4 | 49.4 | 51.3 | 47.2 | 48.7 | 45.9 | 42.8 | 47.0 | 48.4 | 47.1 | 42.5 | 43.2 | 48.3 | 50.3 | 9.1 |
| 5 | *Deepseek-R1 | 2025-01-20 | 47.0 | 47.4 | 45.2 | 45.9 | 46.5 | 49.9 | 51.0 | 47.3 | 46.9 | 50.1 | 46.0 | 42.2 | 46.4 | 49.1 | 48.9 | 45.5 | 43.3 | 44.7 | 50.2 | 8.8 |
| 6 | *Qwen3-30B-A3B-Thinking | 2025-04-29 | 46.1 | 48.2 | 48.8 | 47.3 | 44.9 | 46.6 | 48.5 | 46.9 | 44.9 | 48.1 | 47.4 | 46.6 | 46.3 | 49.3 | 45.4 | 36.3 | 43.6 | 45.2 | 46.1 | 13.1 |
| 7 | *QwQ-32B | 2025-03-06 | 45.9 | 52.1 | 47.5 | 41.3 | 44.9 | 51.0 | 52.2 | 49.4 | 47.3 | 49.3 | 39.9 | 40.0 | 48.7 | 48.7 | 43.6 | 41.0 | 38.5 | 41.3 | 49.2 | 13.7 |
| 8 | *Qwen3-14B-Thinking | 2025-04-29 | 45.8 | 48.9 | 48.0 | 46.6 | 45.2 | 48.1 | 50.3 | 44.2 | 45.3 | 47.0 | 45.7 | 46.0 | 46.4 | 46.7 | 46.4 | 37.2 | 42.2 | 44.4 | 45.8 | 13.1 |
| 9 | *OpenAI-o4-mini-medium | 2025-04-16 | 45.6 | 48.4 | 48.0 | 42.9 | 44.0 | 43.9 | 46.5 | 46.9 | 42.4 | 49.9 | 45.7 | 45.2 | 43.6 | 48.4 | 48.5 | 43.9 | 40.1 | 42.3 | 49.2 | 9.8 |
| 10 | *Qwen3-8B-Thinking | 2025-04-29 | 42.7 | 49.3 | 43.4 | 44.9 | 39.4 | 43.6 | 43.7 | 45.3 | 43.8 | 46.1 | 44.7 | 42.3 | 44.7 | 44.8 | 37.7 | 30.0 | 40.3 | 41.3 | 42.9 | 19.3 |
| 11 | *Qwen3-4B-Thinking | 2025-04-29 | 40.0 | 47.3 | 40.0 | 41.2 | 37.5 | 43.1 | 42.3 | 40.2 | 41.2 | 44.5 | 40.7 | 40.6 | 40.0 | 44.2 | 36.6 | 24.4 | 34.7 | 39.4 | 42.2 | 22.8 |
| 12 | *OpenAI-o1 | 2024-12-05 | 38.9 | 36.9 | 40.7 | 41.0 | 38.9 | 38.5 | 40.5 | 39.2 | 39.0 | 38.7 | 40.4 | 36.2 | 34.8 | 41.6 | 45.1 | 38.7 | 37.2 | 35.9 | 37.4 | 10.2 |
| 13 | *OpenAI-o3-mini-medium | 2025-01-31 | 38.6 | 40.9 | 40.4 | 40.5 | 36.6 | 40.9 | 37.9 | 37.7 | 39.5 | 39.2 | 40.8 | 39.5 | 38.8 | 36.1 | 31.2 | 42.1 | 35.0 | 37.4 | 40.3 | 10.9 |
| 14 | *Gemini-2.0-flash-thinking | 2025-01-21 | 37.1 | 40.4 | 37.0 | 36.5 | 35.4 | 38.4 | 39.8 | 38.8 | 37.7 | 40.5 | 33.0 | 33.9 | 37.9 | 38.6 | 38.3 | 36.7 | 31.8 | 37.6 | 35.3 | 8.6 |
| 15 | *OpenAI-o1-mini | 2024-09-12 | 36.6 | 37.7 | 38.7 | 37.9 | 35.1 | 36.6 | 38.0 | 36.6 | 35.4 | 39.0 | 38.5 | 36.8 | 35.2 | 36.4 | 36.9 | 35.3 | 32.6 | 36.0 | 35.5 | 6.4 |
| 16 | *grok-3 | --- | 35.2 | 41.2 | 35.6 | 32.2 | 32.2 | 38.7 | 38.7 | 36.4 | 35.5 | 36.9 | 28.4 | 31.3 | 37.2 | 38.7 | 35.8 | 35.5 | 30.3 | 32.2 | 36.3 | 12.8 |
| 17 | *DeepSeek-R1-Distill-Qwen-32B | --- | 35.1 | 46.9 | 32.2 | 34.1 | 26.0 | 37.9 | 37.6 | 38.2 | 36.6 | 44.2 | 31.4 | 37.3 | 40.5 | 38.3 | 33.0 | 25.5 | 17.0 | 36.7 | 38.5 | 30.0 |
| 18 | *Claude-3.7-sonnet-thinking | 2025-02-19 | 33.5 | 35.7 | 32.6 | 34.6 | 33.7 | 32.3 | 30.2 | 32.7 | 34.0 | 34.6 | 34.2 | 32.8 | 34.8 | 31.8 | 35.6 | 34.2 | 30.9 | 36.0 | 31.5 | 5.8 |
| 19 | *grok-3-mini | --- | 32.3 | 37.2 | 34.0 | 31.2 | 29.9 | 32.5 | 36.4 | 33.8 | 32.3 | 33.1 | 30.9 | 33.1 | 33.0 | 31.6 | 31.0 | 29.5 | 27.7 | 33.8 | 30.5 | 9.4 |
| 20 | Deepseek-v3-0324 | 2025-03-24 | 30.7 | 30.3 | 28.3 | 31.2 | 33.2 | 25.8 | 32.9 | 31.9 | 30.5 | 32.4 | 33.4 | 28.4 | 34.7 | 24.1 | 28.7 | 30.3 | 33.0 | 32.4 | 30.7 | 10.6 |
| 21 | *DeepSeek-R1-Distill-Llama-70B | --- | 29.4 | 41.8 | 30.7 | 31.6 | 19.9 | 33.0 | 28.5 | 31.5 | 29.7 | 36.7 | 23.7 | 30.1 | 27.1 | 31.8 | 31.0 | 17.3 | 17.7 | 32.5 | 33.9 | 24.5 |
| 22 | GPT-4.1-mini | 2025-04-14 | 28.8 | 33.2 | 28.3 | 26.8 | 25.9 | 31.4 | 32.2 | 29.1 | 30.5 | 29.8 | 28.8 | 26.9 | 30.1 | 29.9 | 31.5 | 25.1 | 23.6 | 27.5 | 27.9 | 9.6 |
| 23 | *DeepSeek-R1-Distill-Qwen-14B | --- | 28.6 | 37.4 | 30.5 | 33.2 | 30.2 | 32.6 | 24.3 | 26.3 | 32.9 | 37.1 | 17.5 | 31.9 | 34.9 | 32.1 | 24.5 | 6.4 | 25.9 | 35.1 | 21.1 | 31.0 |
| 24 | *DeepSeek-R1-Distill-Qwen-7B | --- | 28.3 | 32.3 | 26.1 | 28.4 | 27.1 | 29.0 | 30.7 | 30.6 | 31.3 | 34.5 | 22.2 | 31.1 | 32.3 | 35.5 | 24.5 | 13.8 | 21.5 | 29.0 | 29.3 | 21.7 |
| 25 | Qwen3-235B-A22B-Non-thinking | 2025-04-29 | 27.0 | 28.4 | 24.7 | 28.2 | 25.2 | 25.9 | 29.5 | 28.1 | 27.5 | 28.6 | 26.9 | 27.9 | 28.6 | 28.3 | 26.1 | 24.0 | 23.0 | 27.6 | 27.1 | 6.6 |
| 26 | GPT-4.5-Preview | 2025-02-27 | 26.9 | 31.1 | 28.6 | 26.5 | 25.3 | 25.6 | 26.9 | 28.1 | 27.5 | 29.0 | 26.6 | 25.4 | 27.4 | 27.8 | 29.3 | 25.0 | 23.1 | 24.1 | 27.8 | 8.0 |
| 27 | GPT-4.1 | 2025-04-14 | 26.4 | 33.0 | 25.7 | 23.1 | 24.2 | 29.6 | 28.1 | 26.3 | 28.2 | 28.6 | 25.7 | 24.1 | 24.4 | 26.6 | 26.3 | 24.9 | 23.4 | 24.6 | 28.4 | 9.9 |
| 28 | Llama-4-Maverick | 2025-04-05 | 26.1 | 29.9 | 28.4 | 25.6 | 22.6 | 25.5 | 27.0 | 26.0 | 27.9 | 28.3 | 23.2 | 24.8 | 26.5 | 28.4 | 25.8 | 23.3 | 23.1 | 25.7 | 27.3 | 7.3 |
| 29 | *Qwen3-1.7B-Thinking | 2025-04-29 | 25.2 | 30.6 | 25.8 | 25.8 | 21.4 | 26.8 | 30.2 | 28.7 | 26.8 | 29.6 | 28.5 | 25.2 | 27.4 | 28.2 | 22.8 | 11.0 | 14.7 | 23.7 | 26.9 | 19.6 |
| 30 | ChatGPT-4o-latest | 2025-03-26 | 24.3 | 27.9 | 26.9 | 23.0 | 23.1 | 24.7 | 25.4 | 26.7 | 24.2 | 27.0 | 21.8 | 22.9 | 24.6 | 23.6 | 25.4 | 22.0 | 22.4 | 21.7 | 23.6 | 6.2 |
| 31 | Qwen3-30B-A3B-Non-thinking | 2025-04-29 | 22.9 | 27.8 | 27.0 | 22.6 | 20.8 | 25.2 | 25.0 | 27.3 | 25.9 | 24.8 | 20.6 | 20.7 | 24.3 | 24.0 | 21.1 | 11.9 | 16.0 | 22.3 | 24.7 | 15.8 |
| 32 | Qwen3-32B-Non-thinking | 2025-04-29 | 22.5 | 25.4 | 25.0 | 25.4 | 21.0 | 21.9 | 24.7 | 23.0 | 24.3 | 23.0 | 20.5 | 21.2 | 23.4 | 23.9 | 23.3 | 16.6 | 17.8 | 22.2 | 21.8 | 8.9 |
| 33 | Qwen3-14B-Non-thinking | 2025-04-29 | 22.0 | 24.3 | 21.6 | 23.5 | 18.4 | 24.5 | 25.0 | 24.4 | 24.6 | 27.6 | 19.8 | 18.7 | 23.7 | 25.8 | 24.2 | 12.9 | 14.1 | 22.1 | 21.6 | 14.8 |
| 34 | Qwen2.5-Math-72B-Instruct | --- | 21.0 | 21.2 | 22.0 | 22.5 | 20.9 | 22.0 | 21.8 | 23.6 | 19.4 | 22.0 | 20.2 | 20.6 | 21.8 | 22.0 | 19.7 | 17.5 | 17.9 | 20.9 | 21.3 | 6.1 |
| 35 | Llama-4-Scout | 2025-04-05 | 20.9 | 23.8 | 21.1 | 21.3 | 21.7 | 22.1 | 20.7 | 21.1 | 23.1 | 23.8 | 19.7 | 16.5 | 21.9 | 23.7 | 20.2 | 17.0 | 18.1 | 18.8 | 22.1 | 7.3 |
| 36 | Deepseek-v3 | 2024-12-26 | 20.4 | 21.5 | 21.1 | 21.5 | 17.6 | 20.1 | 22.1 | 22.6 | 20.2 | 22.6 | 21.0 | 19.6 | 21.3 | 20.4 | 21.0 | 19.0 | 15.7 | 20.3 | 20.3 | 6.9 |
| 37 | Gemma-3-27b-IT | --- | 20.3 | 24.1 | 18.5 | 22.8 | 19.0 | 20.2 | 22.4 | 21.5 | 22.6 | 20.5 | 17.3 | 18.3 | 19.5 | 20.9 | 21.6 | 19.1 | 17.0 | 19.0 | 20.6 | 7.1 |
| 38 | Claude-3.7-sonnet | 2025-02-19 | 19.7 | 22.3 | 21.2 | 21.0 | 17.2 | 20.5 | 20.6 | 20.9 | 21.2 | 20.6 | 17.2 | 16.8 | 20.8 | 19.8 | 18.8 | 19.3 | 17.3 | 19.0 | 20.5 | 5.5 |
| 39 | Qwen-2.5-Max | --- | 19.4 | 22.1 | 17.4 | 20.8 | 16.1 | 20.1 | 21.2 | 20.8 | 20.8 | 20.2 | 17.1 | 19.0 | 20.6 | 20.6 | 20.1 | 17.3 | 16.9 | 18.1 | 19.3 | 6.0 |
| 40 | Qwen3-8B-Non-thinking | 2025-04-29 | 18.8 | 22.3 | 17.2 | 16.4 | 14.8 | 19.9 | 21.3 | 21.4 | 21.6 | 23.8 | 18.5 | 16.3 | 19.1 | 19.7 | 22.8 | 14.7 | 13.0 | 17.2 | 19.1 | 10.8 |
| 41 | Phi-4 | --- | 17.4 | 19.1 | 19.1 | 15.7 | 14.1 | 18.3 | 16.8 | 20.5 | 17.4 | 18.0 | 16.9 | 18.0 | 17.7 | 18.4 | 18.8 | 14.6 | 14.7 | 15.8 | 18.4 | 6.4 |
| 42 | Qwen2.5-72B-Instruct | --- | 16.9 | 19.8 | 18.1 | 15.6 | 17.7 | 16.3 | 19.6 | 14.7 | 19.3 | 18.8 | 15.7 | 16.6 | 16.7 | 17.7 | 17.7 | 11.3 | 13.3 | 17.4 | 18.6 | 8.5 |
| 43 | GPT-4o | 2024-11-20 | 13.7 | 15.5 | 17.1 | 12.9 | 12.7 | 13.5 | 15.5 | 15.3 | 14.7 | 15.2 | 12.5 | 12.9 | 13.9 | 15.0 | 13.7 | 12.4 | 9.3 | 11.9 | 13.0 | 7.7 |
| 44 | Llama-3.3-70B-Instruct | --- | 11.5 | 21.0 | 9.9 | 9.7 | 6.5 | 11.1 | 11.2 | 11.0 | 12.5 | 14.4 | 7.0 | 8.4 | 14.5 | 16.0 | 12.1 | 10.5 | 8.3 | 10.9 | 12.1 | 14.5 |
ja: Japanese ko: Korean ms: Malay pt: Portuguese ru: Russian sw: Swahili te: Telugu th: Thai vi: Vietnamese
🚨 We keep updating the results in the leaderboard!
🚨 For more evaluation details, please refer to our paper.